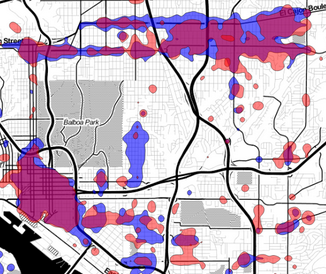
Day/Time Crime Heatmaps
Here is an interactive data application that explores how crime incidents vary over the day of week and time of day. In the checkbox below, select one or more crime types, and the heatmap will show the relative intensity of those crime types over day of week and time of day. There many interesting patterns … Read more