Homeless Encampment Reports
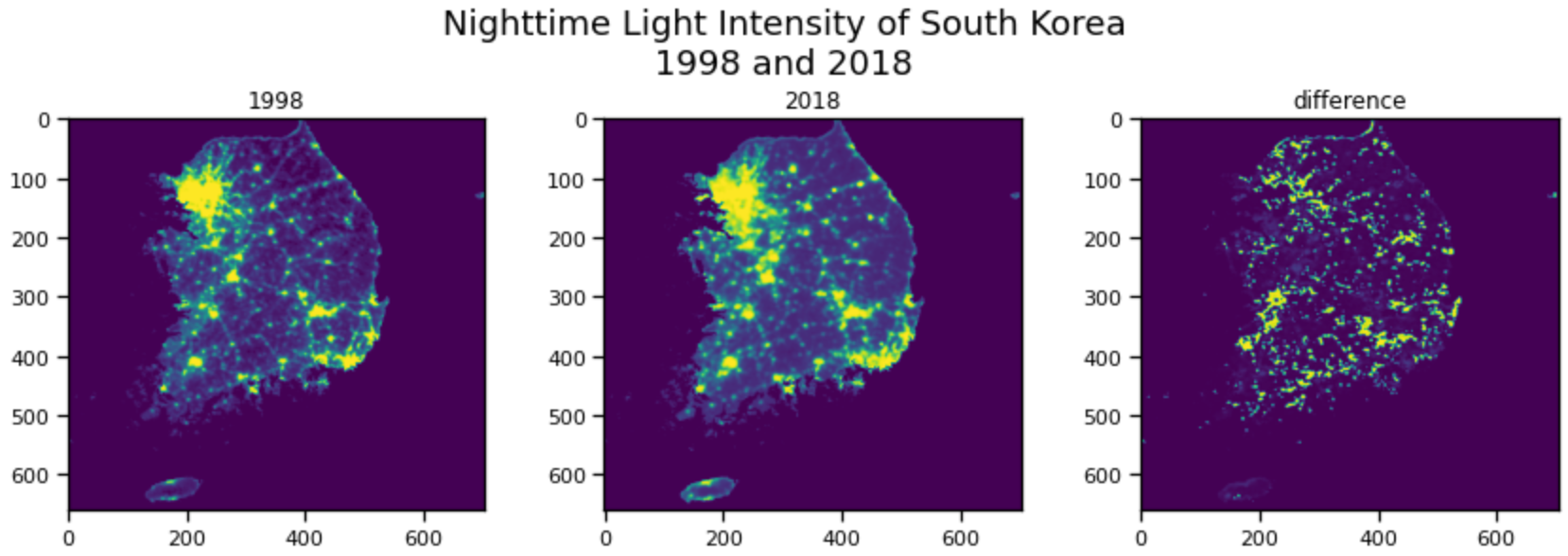
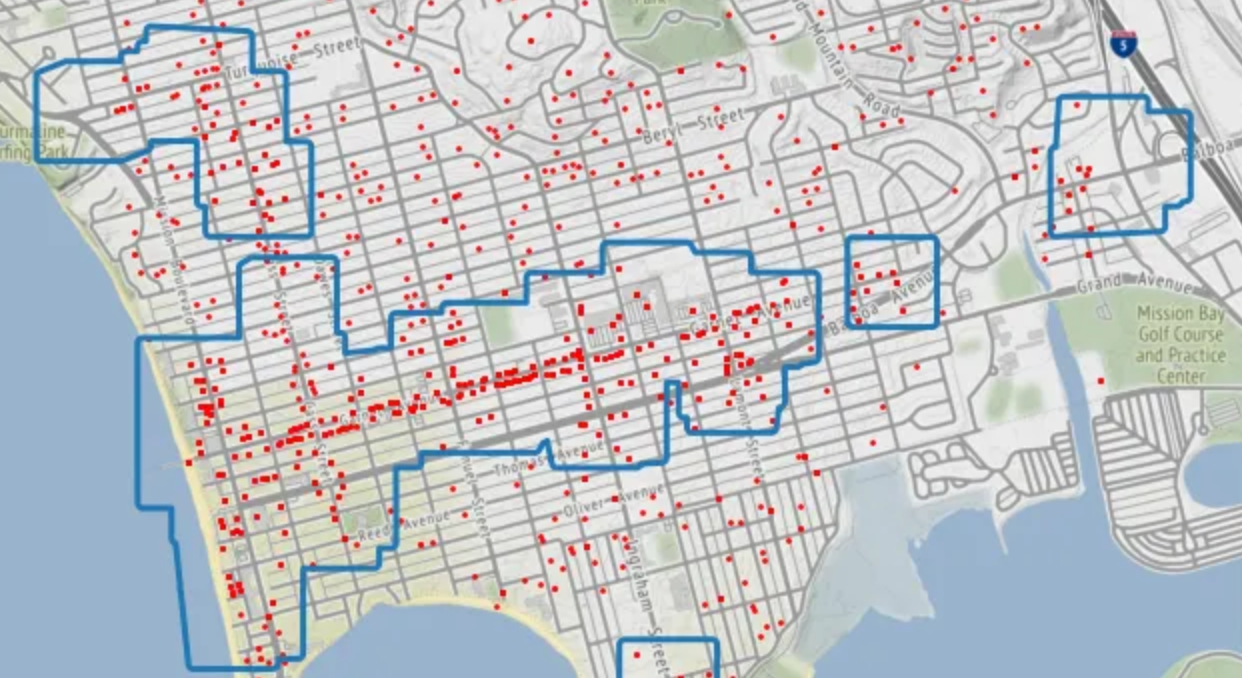
The Library recently added a new dataset, a conversion of the data of reports to the City’s Get It Done program. The dataset includes reports of homeless encampments, so it it an interesting addition to other datasets we have with homeless position reports. Here is a heatmap of positions of reports. The orange dot is … Read more