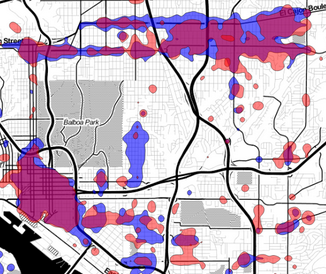
Healthy Food Access Data Library Project
Collect and analyze data about the food system in San Diego county. The San Diego Food System Alliance’s Healthy Food Access Working Group is developing an indicator library to analyze food access issues, and we need your help to locate datasets, wrangle them into useable shape, and create visualizations. The work is similar to the topics … Read more